

TL;DR
- FMEA is a structured, proactive risk tool that identifies how equipment, processes, or systems can fail — and ranks each failure by severity, likelihood, and detectability before an incident occurs.
- It shifts safety from reactive to predictive by forcing teams to ask “what could go wrong?” systematically — not after a fatality investigation, but during design, planning, and routine operations.
- The Risk Priority Number (RPN) is the core output — calculated by multiplying Severity × Occurrence × Detection — and drives where your limited safety resources go first.
- FMEA works across every high-risk industry — from petrochemical process safety and mining equipment reliability to construction crane operations and pharmaceutical manufacturing.
- Most FMEA failures are human, not technical — rushed workshops, vague failure descriptions, and teams that never revisit their analysis after the initial session turn a powerful tool into a dust-collecting spreadsheet.
I was standing in a turbine hall during a planned maintenance shutdown at a gas-fired power station in the Gulf when the lead mechanical engineer handed me a three-ring binder. “This is our FMEA,” he said. The binder was two years old. No updates since commissioning. No link to the permit-to-work system. No connection to the maintenance schedule we were about to execute. Three days later, a lube oil pump failed in a mode that was technically listed on page forty-seven of that binder — but nobody had read it, nobody had assigned controls, and the risk priority number column was blank. The resulting oil spray hit a hot surface. We evacuated the unit. No injuries, but it was close.
That incident crystallized something I’ve seen repeatedly across refineries, construction megaprojects, and manufacturing plants on four continents: Failure Mode and Effects Analysis is one of the most powerful proactive risk assessment tools available to HSE professionals — and one of the most commonly misused. When done properly, FMEA identifies how systems fail before they fail, ranks the risk of each failure mode, and directs resources to the failures that matter most. When done poorly, it becomes a compliance checkbox that sits in a file server while the plant burns. This article breaks down what FMEA actually is, how it works in real operations, where teams get it wrong, and how to make it a living safety tool instead of a dead document.
What Is Failure Mode and Effects Analysis (FMEA)?
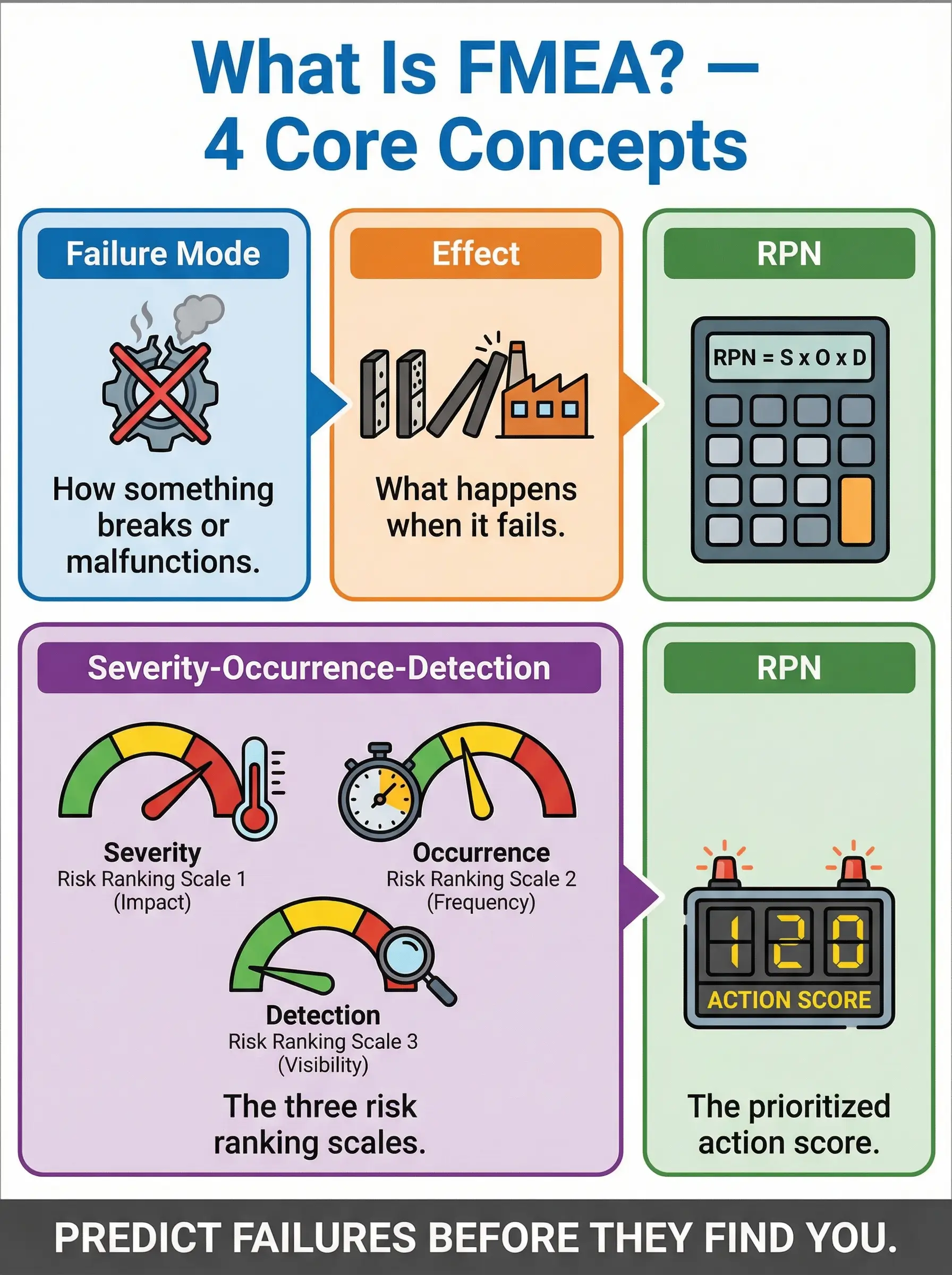
Failure Mode and Effects Analysis is a systematic, step-by-step methodology for identifying all the ways a process, product, system, or piece of equipment can fail, evaluating the consequences of each failure, and prioritizing corrective actions based on risk. Originally developed in the late 1940s by the U.S. military and later adopted by NASA and the automotive industry, FMEA has become a cornerstone of process safety management, reliability engineering, and occupational health and safety risk assessment across virtually every high-hazard sector.
In practical HSE terms, FMEA answers three questions simultaneously for every potential failure:
- How bad is it? The Severity rating captures the worst credible consequence if the failure occurs — from minor operational disruption to a worker fatality or catastrophic environmental release.
- How often could it happen? The Occurrence rating estimates how frequently the failure mode is likely to present itself, based on historical data, equipment reliability records, and operational experience.
- Can we catch it before it hurts someone? The Detection rating evaluates how likely existing controls, inspections, or monitoring systems are to identify the failure before it reaches the worker, the environment, or the public.
These three scores — each rated on a scale of 1 to 10 — are multiplied together to produce the Risk Priority Number (RPN). The RPN is the decision-making engine of the entire process. It tells you which failure modes demand immediate engineering controls, which need improved inspection regimes, and which are adequately managed by current measures. An RPN of 1 means the failure is trivial, nearly impossible, and easily detected. An RPN approaching 1,000 means a catastrophic, likely, and invisible failure is waiting to happen.
OSHA’s Process Safety Management standard (29 CFR 1910.119) requires employers to conduct a process hazard analysis using one or more recognized methodologies. FMEA is explicitly listed as an acceptable PHA method alongside HAZOP, What-If, Checklist, and Fault Tree Analysis. [External Link: https://www.osha.gov/process-safety-management]
Pro Tip: The RPN number itself is not the whole story. I’ve seen teams fixate on reducing an RPN from 280 to 140 and declare victory — while ignoring a failure mode with an RPN of 90 that had a Severity score of 10 (fatality potential). Always look at the individual Severity score first. Any failure mode with a Severity of 9 or 10 demands action regardless of the overall RPN.
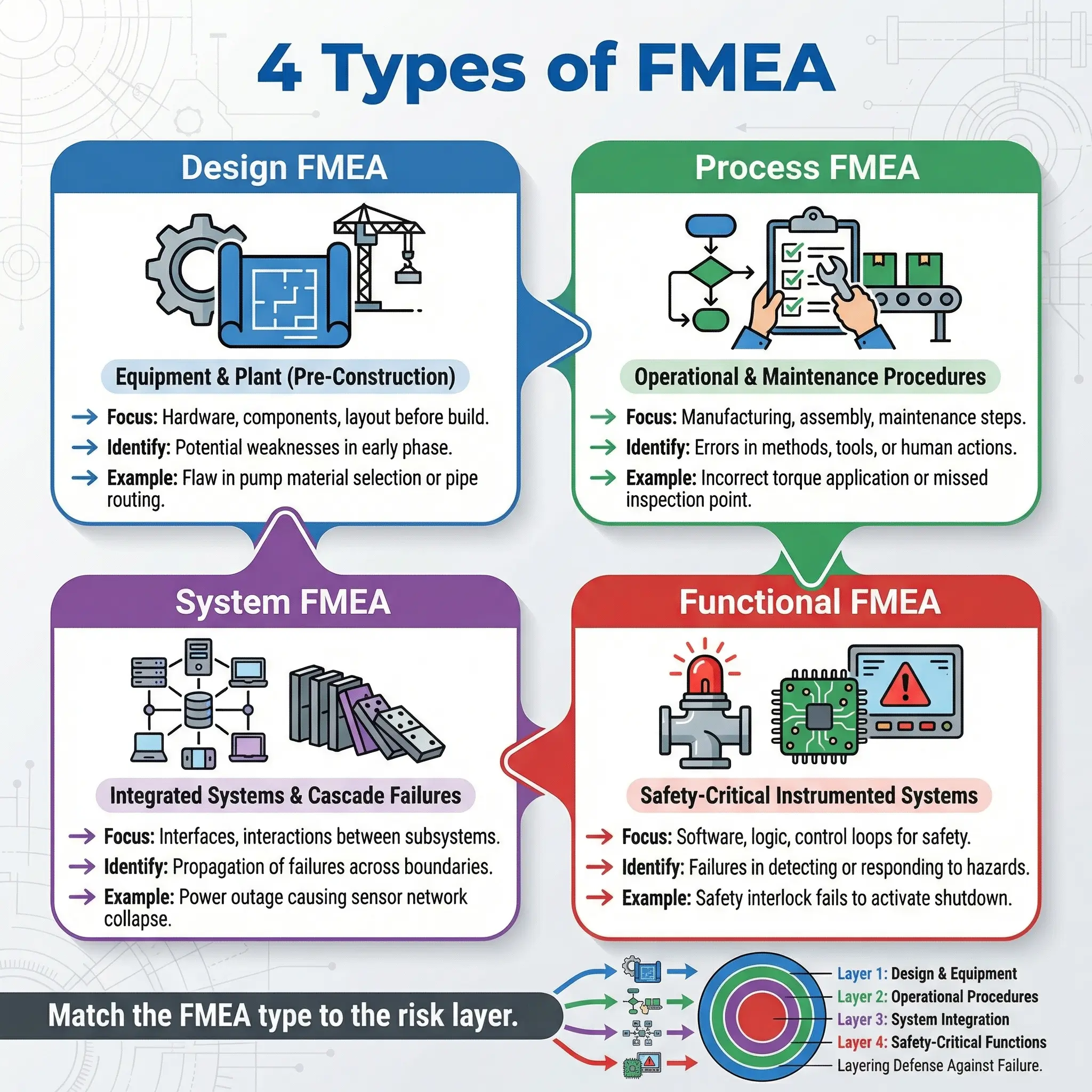
Types of FMEA and Where Each Applies in HSE
FMEA is not a single monolithic tool. Different variants exist, and selecting the right type determines whether your analysis actually prevents incidents or just produces paperwork. Each type focuses on a different layer of the operational system.
The following are the primary FMEA types encountered in HSE practice, along with the real-world contexts where each delivers the most value:
- Design FMEA (DFMEA): Analyzes potential failure modes in the design phase of equipment, plant, or systems — before anything is built or installed. I used this extensively during the front-end engineering design (FEED) phase of a petrochemical expansion in Southeast Asia, identifying seventeen critical failure modes in the cooling water system design that would have been exponentially more expensive to fix after construction.
- Process FMEA (PFMEA): Focuses on failures in manufacturing, operational, or maintenance processes — the steps humans and machines perform to produce output. This is the most common type in HSE work. It captures failures in work procedures, standard operating procedures, and permit-to-work sequences.
- System FMEA (SFMEA): Examines failures at the full system level, including how subsystem failures interact and cascade. Essential for process safety in refineries, chemical plants, and offshore platforms where a single valve failure can trigger a chain reaction across interconnected systems.
- Functional FMEA: Evaluates failure modes based on the intended function of a component or system — what it’s supposed to do versus how it can fail to do it. Particularly useful for safety-critical instrumented systems (SIS) and emergency shutdown (ESD) systems where the function IS the safety barrier.
The following table clarifies which FMEA type matches common HSE applications:
| FMEA Type | Primary HSE Application | When to Use | Typical Industry |
|---|---|---|---|
| Design FMEA | New equipment, plant modifications, safety system design | FEED phase, Management of Change (MOC) | Oil & gas, chemical, power generation |
| Process FMEA | Operational procedures, maintenance tasks, permit-to-work | Ongoing operations, pre-task risk assessment | Manufacturing, construction, mining |
| System FMEA | Integrated plant systems, cascading failure scenarios | Process safety reviews, major hazard installations | Petrochemical, offshore, nuclear |
| Functional FMEA | Safety instrumented systems, emergency shutdown logic | SIL verification, safety barrier validation | Process industries, aerospace |
How FMEA Works — The Step-by-Step Process
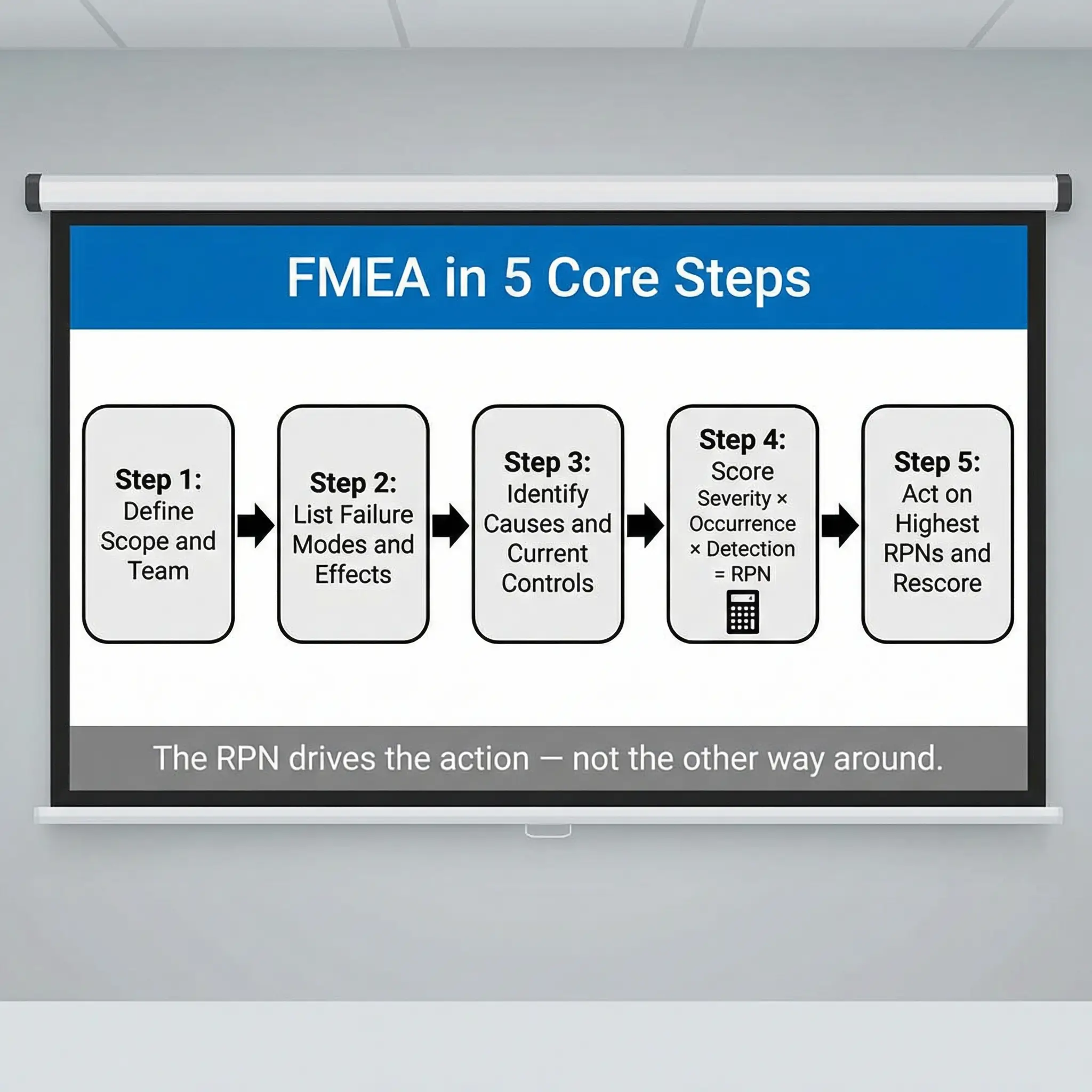
Understanding the FMEA methodology on paper is straightforward. Executing it well on a real site with real time pressures and real operational politics is where most teams struggle. The following sequence is the standard approach I’ve facilitated across more than forty FMEA workshops in refinery turnarounds, mining operations, and EPC construction projects.
Each step builds on the previous one, and skipping or rushing any step degrades the entire analysis:
- Define the scope and boundaries. Identify exactly which system, process, equipment, or procedure you’re analyzing. A common early mistake is scoping too broadly — “the entire cooling tower system” — when the analysis should focus on a specific subsystem or operational mode. I define scope by asking: “What is the specific function we need this thing to perform, and what are we worried about it failing to do?”
- Assemble the right team. FMEA is a team exercise, not a desk exercise. The workshop must include the equipment operator, a maintenance technician with hands-on experience, a process or design engineer, and an HSE professional. I also pull in the permit-to-work coordinator when analyzing maintenance-phase failures. The people who touch the equipment daily know failure modes that no engineering drawing will show you.
- Identify all potential failure modes. For each component or process step, systematically list every way it could fail to perform its intended function. This includes complete failure (pump stops running), partial failure (pump delivers reduced flow), intermittent failure (pump cavitates under certain conditions), and unintended function (pump runs backward after power restoration). This step requires patience and discipline — the team must resist the urge to jump to causes or solutions.
- Determine the effects of each failure. For every failure mode identified, describe what happens next — both the local effect (what the operator sees or experiences immediately) and the system-level effect (what happens downstream, including safety, environmental, and operational consequences). During a workshop at a mining concentrator plant, we identified that a single conveyor belt misalignment failure mode had three entirely different effect pathways depending on whether the plant was in normal operation, startup, or emergency shutdown.
- Identify the root causes of each failure mode. What conditions, degradation mechanisms, human errors, or design weaknesses cause this failure to occur? Each failure mode may have multiple independent causes — and each cause gets its own Occurrence rating. This is where maintenance history, incident records, and operator experience become critical data inputs.
- List current controls. Document the existing prevention controls (what stops the failure from happening) and detection controls (what catches the failure before it reaches the consequence) already in place. Be brutally honest here. “Operator vigilance” is not a control. “Daily visual inspection per checklist XYZ with sign-off” is.
- Score Severity, Occurrence, and Detection. Apply the 1–10 rating scales to each failure mode. Use standardized scoring criteria — not gut feel. I carry a calibrated scoring table specific to the industry context into every workshop and display it on-screen throughout the session.
- Calculate the Risk Priority Number. Multiply S × O × D to get the RPN for each failure mode. Sort the list from highest to lowest RPN. The top-ranked items are your priority action items.
- Assign corrective actions with owners and deadlines. For every failure mode above your defined RPN threshold (or with a Severity of 9–10 regardless of RPN), assign a specific corrective action, a named responsible person, and a completion date. Vague actions like “improve maintenance” fail every time. Specific actions like “install vibration monitoring sensor on pump P-301A bearing housing by 15 March with daily trending review by mechanical supervisor” get results.
- Recalculate RPN after actions are implemented. After corrective actions are in place, rescore the failure mode. The new RPN validates whether the action actually reduced the risk. If the RPN hasn’t dropped meaningfully, the action didn’t work — and you need a different approach.
Pro Tip: Never let the workshop exceed four hours without a break. FMEA fatigue is real. After hour three, I’ve watched experienced engineers start scoring every Occurrence as a “3” and every Detection as a “5” just to finish the spreadsheet. Schedule sessions in two-hour blocks with a clear scope target for each block.
Understanding the FMEA Scoring System — Severity, Occurrence, and Detection
The scoring system is where FMEA either gains credibility or collapses into subjective guesswork. Every number in the S-O-D framework must be anchored to defined criteria that the entire team understands and applies consistently. The moment scoring becomes arbitrary, the RPN loses all meaning — and your prioritization becomes random.
Severity Rating (S) — How Bad Is the Consequence?
Severity measures the worst credible outcome if the failure mode occurs and current controls fail to prevent the consequence. This rating is locked to the effect — it does not change based on how often the failure happens or whether you can detect it. A failure that kills a worker is always a 10, whether it happens once a decade or once a day.
The following severity scale is calibrated for HSE applications across heavy industry:
| Severity Rating | HSE Consequence Description | Example |
|---|---|---|
| 1 | No safety or environmental impact | Cosmetic defect on non-critical component |
| 2–3 | Minor first-aid injury or negligible environmental effect | Small scrape, minor contained drip |
| 4–5 | Medical treatment injury or minor environmental release | Laceration requiring stitches, small spill within bunded area |
| 6–7 | Serious injury (lost time) or significant environmental impact | Fracture, hospitalization, reportable spill |
| 8 | Severe injury or major environmental damage | Permanent disability, large uncontained release |
| 9 | Life-threatening injury or critical environmental catastrophe | Single fatality potential, major ecosystem damage |
| 10 | Multiple fatalities or irreversible environmental disaster | Explosion, toxic cloud release, mass casualty event |
Occurrence Rating (O) — How Likely Is the Failure?
Occurrence estimates the probability that a specific cause will produce the failure mode during the defined operational period. This rating should be driven by data wherever possible — maintenance records, mean time between failures (MTBF), incident logs, and industry reliability databases.
The challenge I encounter most frequently is teams scoring Occurrence based on memory rather than records. On a turnaround project in the Middle East, the operations team rated a specific heat exchanger tube leak as “unlikely — maybe a 2.” The maintenance database showed seven tube leak work orders in the previous eighteen months. The actual Occurrence score was an 8. Data beats memory every time.
- 1: Failure is virtually eliminated through proven design — less than 1 in 1,000,000 operations
- 2–3: Very low probability — isolated incidents in historical records
- 4–5: Low to moderate — occasional failures documented in maintenance history
- 6–7: Moderate to high — repeated failures are a known operational issue
- 8–9: High to very high — failure occurs frequently and is expected
- 10: Near-certain — failure is inevitable without design change
Detection Rating (D) — Can You Catch It Before It Hurts Someone?
Detection is the most commonly misunderstood score. It rates the effectiveness of your current controls at identifying the failure mode before it reaches the consequence — not whether the failure has occurred, but whether your systems will catch it in time. A low Detection score (1–2) means your current monitoring, inspection, or testing regime will almost certainly catch the failure. A high Detection score (9–10) means the failure is invisible until someone gets hurt.
This is where I push teams hardest. In a PFMEA for a batch chemical reactor operation, the team initially scored the Detection for a runaway reaction scenario as “4” because they had a temperature alarm on the reactor. When I asked what the alarm setpoint was, how fast the temperature could rise, how long an operator needed to respond, and what physical action was required — the realistic Detection score moved to a 7. The alarm existed, but the detection-to-intervention chain was too slow to prevent the consequence.
- 1–2: Near-certain detection — automated shutdown, continuous monitoring with immediate response
- 3–4: High detection — regular quantitative testing, calibrated instrumentation with alarms
- 5–6: Moderate detection — periodic inspection, visual checks, operator rounds
- 7–8: Low detection — detection relies on human observation or infrequent testing
- 9–10: Virtually undetectable — no current control exists, or failure is hidden until consequence occurs

Common Mistakes That Destroy FMEA Effectiveness
I’ve audited and facilitated enough FMEA sessions to recognize the patterns that turn a world-class risk tool into a worthless spreadsheet. The failures are rarely technical — they’re organizational, behavioral, and cultural. Understanding these failure modes is itself a meta-lesson in how safety systems break down.
The following mistakes account for the vast majority of ineffective FMEAs I’ve encountered across industries:
- Vague failure mode descriptions. Writing “pump fails” instead of “pump P-301A experiences bearing seizure due to loss of lubrication during extended dry-run condition.” The level of specificity in the failure mode description determines whether the analysis produces useful actions or generic platitudes. Every failure mode should answer: what component, what type of failure, under what conditions.
- Scoring by consensus pressure instead of data. In workshop settings, the most senior person’s opinion often becomes the score. I’ve watched a plant manager override a maintenance technician’s Occurrence rating because admitting the failure was common would reflect poorly on his maintenance budget. Use data. Print the maintenance history. Put the evidence on the table before scoring begins.
- Treating FMEA as a one-time exercise. The most damaging mistake of all. FMEA is a living document that must be updated when equipment is modified, when operating conditions change, when a near-miss reveals a failure mode not previously identified, and at a minimum during every Management of Change (MOC) review. The binder I found in that turbine hall — untouched for two years — is the norm, not the exception.
- Ignoring high Severity scores because the RPN is low. A failure mode with S=10, O=1, D=1 gives an RPN of 10. That sits at the bottom of the priority list. But if that failure occurs, someone dies. Any Severity of 9 or 10 must trigger mandatory action regardless of the calculated RPN. I flag these in red in every workshop and assign them separately from the RPN ranking.
- Confusing prevention controls with detection controls. A pressure relief valve prevents overpressure. A pressure gauge detects overpressure. Mixing these up corrupts both the Occurrence and Detection scores. The team must clearly separate what stops the failure from what finds the failure.
- Assembling the wrong team. Engineers designing a system in a conference room without operators, maintainers, or HSE professionals will produce an elegant but incomplete analysis. The people who operate, maintain, and supervise the system daily identify failure modes that never appear on P&IDs or equipment specifications.
- Never following through on actions. Assigning 47 corrective actions in a workshop and tracking zero of them to completion. I now embed FMEA actions directly into the site’s corrective action tracking system with the same escalation protocols as audit findings and incident actions. If it’s not tracked, it doesn’t happen.
ISO 45001:2018 Clause 6.1 requires organizations to determine risks and opportunities for the OH&S management system and to plan actions to address them. FMEA — when maintained as a living document — directly fulfills this requirement by providing a systematic, scored, and tracked risk treatment process. [External Link: https://www.iso.org/standard/45001]
Pro Tip: At the end of every FMEA workshop, I ask the team one question: “If I come back in six months and look at this spreadsheet, will the actions be closed?” If the room goes quiet, the problem is not the FMEA — it’s the management system behind it. Fix the tracking before you schedule the next workshop.

FMEA vs. Other HSE Risk Assessment Methods
FMEA does not exist in isolation. HSE professionals have a toolkit of risk assessment methodologies, and choosing the right tool — or the right combination — depends on the hazard type, the system complexity, and the decision you need to make. I’ve seen teams force-fit FMEA into situations where a HAZOP or bowtie analysis would have been far more effective, and vice versa.
The following comparison positions FMEA against the methods most commonly used in high-hazard industries:
| Method | Best For | Strengths | Limitations | Typical Application |
|---|---|---|---|---|
| FMEA | Equipment and process failure modes | Systematic, scored, prioritized, action-oriented | Does not model failure interactions or cascading events well | Equipment reliability, maintenance planning, design review |
| HAZOP | Process deviations in continuous systems | Examines deviations from design intent using guidewords | Time-intensive, requires P&ID maturity | Chemical plants, refineries, gas processing |
| Bowtie Analysis | Visualizing barrier effectiveness for major hazard scenarios | Clear threat-barrier-consequence structure | Qualitative unless integrated with quantitative data | Major accident hazard management, process safety |
| Fault Tree Analysis (FTA) | Understanding how multiple failures combine to cause a top event | Models complex failure combinations and common cause failures | Requires reliability data, mathematically intensive | Nuclear, aerospace, SIL verification |
| Job Hazard Analysis (JHA) | Task-level hazard identification for frontline workers | Simple, practical, worker-involved | Limited scope, no scoring system, no failure interaction | Construction tasks, maintenance activities, routine operations |
The critical distinction is this: FMEA excels at individual failure mode identification and prioritization. It answers “what can fail and how bad is it?” with precision. It does not answer “how do multiple failures combine to cause a catastrophic event?” — that’s where Fault Tree Analysis and bowtie models take over. In practice, I use FMEA as the foundation layer and feed its high-severity failure modes into bowtie analyses for major hazard scenarios.
Applying FMEA in Real HSE Operations — Field Applications
Theory means nothing if it doesn’t change what happens on the ground. The following applications reflect how I’ve deployed FMEA in active operations — not as academic exercises, but as tools that directly prevented incidents, reduced downtime, and improved safety barrier reliability.
Pre-Turnaround and Shutdown Safety Planning
Major turnarounds and shutdowns concentrate high-risk work — hot work, confined space entry, heavy lifts, simultaneous operations — into compressed timescales. FMEA applied to the turnaround work scope identifies which equipment failure modes are most likely to cause safety incidents during the maintenance window. On a refinery catalytic cracker turnaround, I facilitated a Process FMEA on the reactor vessel entry sequence that identified a failure mode in the nitrogen purge verification step. The existing procedure relied on a single atmospheric test at the manhole — but the vessel geometry created a pocket where residual hydrocarbon vapor could stratify. We added a secondary test point requirement at the lowest internal elevation before any entry permit was issued.
Management of Change (MOC) Risk Evaluation
Every plant modification — whether a hardware change, a procedural change, or an organizational change — introduces new failure modes. FMEA is the natural risk assessment companion to MOC because it systematically asks what can fail differently after the change. During an MOC for replacing a mechanical seal on a reactor feed pump with a different seal type at a chemical plant, a Design FMEA identified that the new seal’s maximum temperature rating was 15°C below the peak process temperature during exothermic runaway conditions. That failure mode — seal failure during emergency conditions — would have been invisible to a standard MOC checklist.
Construction Safety — Temporary Works and Lifting Operations
Temporary works — falsework, shoring, scaffolding, temporary electrical systems — are designed to be removed, which means they often receive less engineering scrutiny than permanent installations. Applying FMEA to temporary works identifies failure modes that standard risk assessments miss. I applied a System FMEA to a heavy lift plan for a 280-tonne vessel installation on a greenfield construction site and identified that the crane outrigger pad design assumed a soil bearing capacity that had not been verified for the specific pad location after recent heavy rainfall. The Severity was 10, the Detection score was 9 (no geotechnical verification was in the lift plan), and the corrective action — a geotechnical survey with revised pad design — was completed before the lift proceeded.
Safety-Critical Equipment Maintenance Prioritization
When maintenance budgets are limited — and they always are — FMEA provides the evidence-based rationale for prioritizing which equipment gets attention first. The RPN ranking directly supports risk-based maintenance strategies by identifying which failure modes carry the highest combined consequence, likelihood, and detection gap. I used this approach at a mining operation to justify bringing forward a crusher gearbox inspection that had been deferred three times due to production pressure. The FMEA showed the gearbox bearing failure mode had an RPN of 630 with a Severity of 9. The inspection was approved and conducted — and found a bearing race crack that was two shifts away from catastrophic failure.

Building a Sustainable FMEA Program — Making It Live Beyond the Workshop
The single greatest failure in FMEA implementation is not a scoring error or a missed failure mode — it’s abandonment. Most organizations conduct an initial FMEA with great energy, produce a beautifully formatted spreadsheet, and never open it again. Twelve months later, someone gets hurt in a failure mode that was identified, scored, and theoretically controlled in a document that nobody reviewed.
Sustaining FMEA as a living safety tool requires embedding it into the management system, not running it as a standalone project. The following practices have consistently produced sustainable FMEA programs in organizations I’ve worked with:
- Link FMEA directly to your corrective action tracker. Every action arising from an FMEA must enter the same tracking system used for audit findings, incident actions, and regulatory deficiencies — with the same escalation, overdue notification, and management review visibility. If FMEA actions live in a separate spreadsheet, they will die there.
- Schedule mandatory review triggers. Define the events that automatically trigger an FMEA review: any incident or near-miss involving equipment in the FMEA scope, any Management of Change affecting the analyzed system, any maintenance finding that reveals a previously unidentified failure mode, and a time-based review at minimum annually. Write these triggers into the site’s HSE management system procedure — not into a workshop report.
- Assign FMEA ownership to operational leadership, not just HSE. The plant manager, maintenance superintendent, or operations director must own the FMEA review schedule and action status. When FMEA is perceived as “an HSE thing,” it loses operational relevance and priority. The most effective programs I’ve seen assign FMEA ownership to the equipment custodian — the person whose production depends on that equipment running safely.
- Integrate FMEA data into pre-task briefings and toolbox talks. Workers don’t read FMEA spreadsheets. But they do attend toolbox talks. Pull the top three failure modes and their controls from the relevant FMEA and present them in plain language during pre-task briefings. This closes the gap between the analytical document and the frontline crew.
- Audit the FMEA process, not just the document. During ISO 45001 or OSHA PSM audits, I don’t just check whether an FMEA exists. I check when it was last reviewed, whether actions are closed, whether the scoring reflects current operational reality, and whether frontline workers are aware of the critical failure modes in their area. A perfect document with zero implementation is a non-conformance.
IFC Performance Standard 4 (Community Health, Safety, and Security) and World Bank EHS Guidelines both require operators to conduct systematic hazard identification and risk assessment proportionate to the nature and scale of the project. FMEA, maintained as a living program, satisfies this requirement with auditable evidence of ongoing risk evaluation. [External Link: https://www.ifc.org/en/insights-reports/2012/ifc-performance-standards]
Pro Tip: Create a one-page “FMEA Dashboard” for each critical system — top five failure modes, current RPNs, action status, last review date. Post it in the control room or maintenance workshop. When the data is visible, accountability follows.

FMEA and Regulatory Compliance — Where It Fits in the Legal Framework
FMEA is not universally mandated by name, but it fulfills hazard analysis and risk assessment requirements embedded in virtually every major occupational safety and process safety regulation. Understanding where FMEA fits legally — and where regulators expect to see its outputs — strengthens both compliance and the business case for investing in the methodology.
The following regulatory frameworks either explicitly reference FMEA or require the type of systematic failure analysis that FMEA delivers:
- OSHA Process Safety Management (29 CFR 1910.119): Lists FMEA as one of the acceptable process hazard analysis (PHA) methodologies under Clause (e). PSM-covered facilities handling highly hazardous chemicals above threshold quantities must conduct initial PHAs and revalidate them at least every five years. FMEA satisfies this requirement when applied to process equipment and systems within the PSM scope. [External Link: https://www.osha.gov/laws-regs/regulations/standardnumber/1910/1910.119]
- EPA Risk Management Program (40 CFR Part 68): Mirrors OSHA PSM requirements for facilities handling regulated substances above threshold quantities. The hazard assessment requirement under RMP Program 3 can be met using FMEA.
- ISO 45001:2018 Clause 6.1.2: Requires organizations to identify hazards, assess risks, and determine controls through a systematic process. While ISO 45001 does not prescribe a specific methodology, FMEA provides the structured, scored, and documented output that auditors expect to see during certification audits.
- IEC 60812: The international standard specifically governing FMEA and FMECA (Failure Mode, Effects, and Criticality Analysis) methodology. This standard provides the procedural framework, terminology, and scoring guidance for conducting FMEA across all industries. It is the technical reference that underpins FMEA application in safety-critical systems.
- UK HSE COMAH Regulations (Control of Major Accident Hazards): Upper-tier COMAH sites must demonstrate that major accident risks have been identified and controlled through a robust safety report. FMEA — particularly for safety-critical equipment and systems — forms a key component of the safety report’s risk assessment evidence.
- EU Machinery Directive (2006/42/EC): Requires manufacturers to conduct risk assessment of machinery covering all foreseeable failure modes and misuse scenarios. FMEA is one of the most commonly used tools for CE marking compliance on industrial machinery sold or operated in the EU.
| Regulation | FMEA Requirement | Scope | Review Frequency |
|---|---|---|---|
| OSHA PSM (1910.119) | Explicitly listed PHA method | Process equipment, HHC systems | Every 5 years minimum |
| EPA RMP (40 CFR 68) | Acceptable hazard assessment method | Regulated substance systems | Every 5 years minimum |
| ISO 45001 Clause 6.1.2 | Systematic risk assessment required (method not prescribed) | All workplace hazards | Ongoing, as risks change |
| IEC 60812 | Defines FMEA/FMECA methodology | All industries | Per project/product lifecycle |
| UK COMAH | Safety report must include failure analysis | Major hazard installations | Review on material change |
| EU Machinery Directive | Foreseeable failure mode analysis required | Machinery design and operation | Pre-market and ongoing |
Conclusion
Failure Mode and Effects Analysis is not a form to fill out — it’s a discipline. When I look at the FMEAs that have actually prevented serious incidents across the projects I’ve worked on, they share three characteristics: they were facilitated by teams who understood the system they were analyzing, they were scored with data instead of opinions, and they were tracked with the same rigor as regulatory enforcement actions. The tool itself is elegant in its simplicity — identify how things fail, score the risk, act on the worst ones first. The execution is where organizations succeed or fail.
The most important thing I want you to take from this article is not the scoring formula or the workshop steps. It’s the commitment to keep the analysis alive. An FMEA that was brilliant on the day of the workshop and sits untouched for two years is not a safety tool — it’s a liability document that proves you knew about the risk and did nothing. Update it when things change. Review it when something goes wrong. Feed its findings into your frontline briefings so the people who actually face the hazard know what can fail and what to watch for.
Every serious incident I’ve investigated had a failure mode that somebody, somewhere, already knew about. The purpose of FMEA is to make sure that knowledge doesn’t stay trapped in someone’s head or buried in a spreadsheet — but reaches the controls, the procedures, and the workers before the failure reaches them first. Safety is not about eliminating every possible failure. It’s about knowing which failures will kill, and ensuring those are the ones you control relentlessly.