

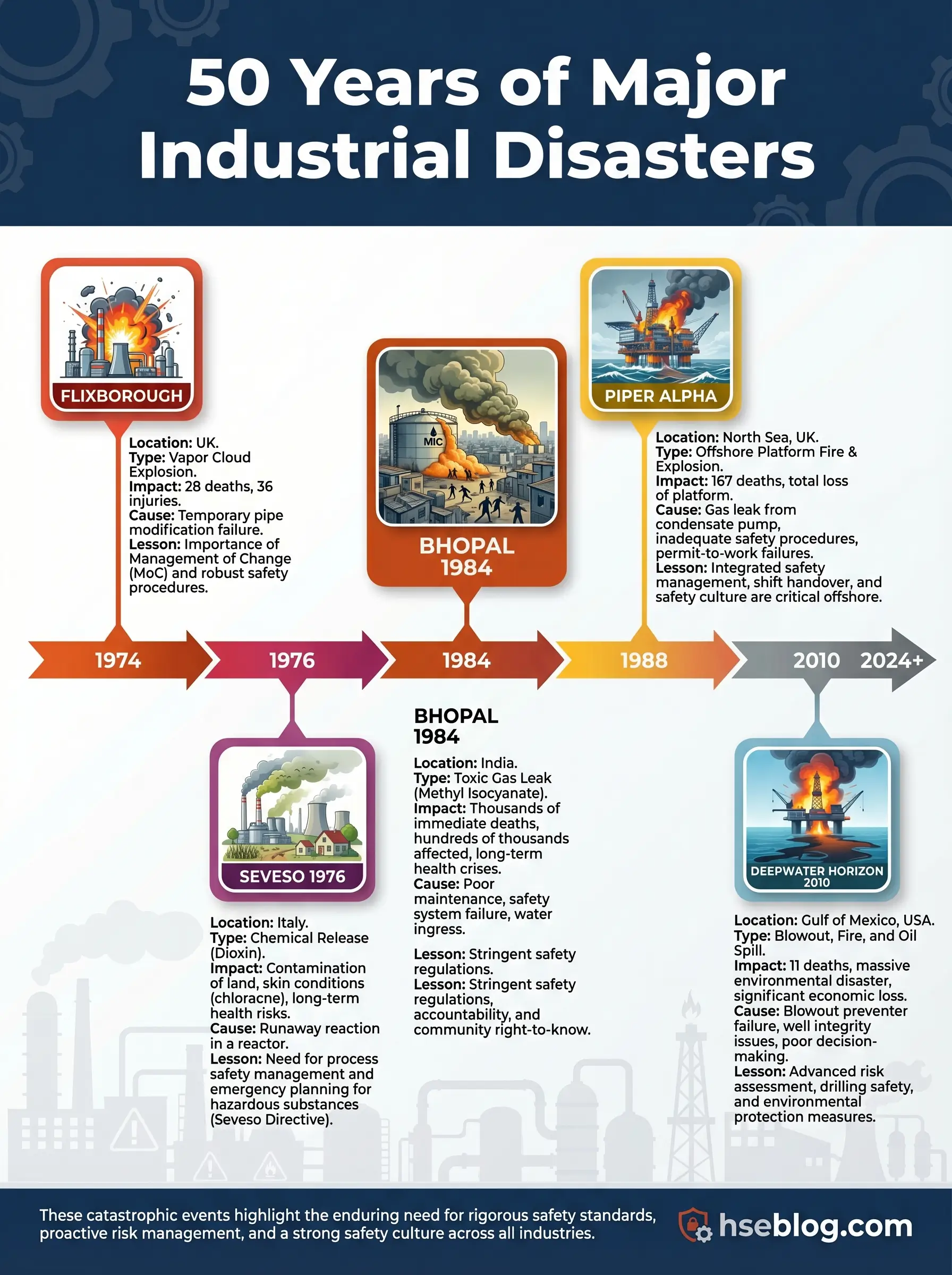
A cloud of cyclohexane vapor found its ignition source at 16:53 on a Saturday afternoon. Twenty-eight chemical plant workers died in the blast that followed. The temporary pipe bypass that caused the release had been installed weeks earlier without a formal engineering review, without stress calculations, and without anyone recognizing that a 20-inch pipe had been replaced by a makeshift assembly that could not withstand normal operating pressure. That was Flixborough, 1974 — and it was only the beginning of a decades-long catalog of industrial catastrophes that would reshape how the world thinks about major accident prevention.
The ten disasters examined here span chemical processing, offshore drilling, fuel storage, nuclear energy, and fertilizer handling. Each killed workers, harmed communities, damaged ecosystems, or triggered regulatory overhauls — often all four at once. This article does not simply retell these events. It dissects the systemic causes behind each one, identifies the specific lesson that matters most, and then pulls the recurring failure patterns together into a prevention framework grounded in current process safety standards. The term major industrial accidents carries legal and operational weight in modern HSE practice, and understanding why these events qualify — and what they demand of us today — separates reactive safety cultures from genuinely resilient ones.
What Makes an Industrial Accident “Major”?
Not every workplace incident qualifies as a major industrial accident, and the distinction matters. Regulators, investigators, and process safety professionals use the term deliberately. It separates the catastrophic from the routine — events where the scale of harm, the nature of the failure, or the breadth of consequence places the incident in a fundamentally different category than a lost-time injury or a contained spill.
The ten cases in this article were selected based on six criteria that reflect how major accident prevention frameworks define severity:
- Mass fatalities or serious injuries: Events that killed or harmed large numbers of workers, emergency responders, or members of the public in a single occurrence.
- Off-site community impact: Toxic releases, explosions, or fires that breached the facility boundary and affected surrounding populations through exposure, evacuation, or long-term health harm.
- Environmental destruction: Large-scale contamination of land, water, or ecosystems that required sustained remediation and caused lasting ecological damage.
- Regulatory consequence: Accidents that directly triggered new legislation, standards, directives, or fundamental changes in how governments regulate industrial risk.
- Cross-sector relevance: Failures rooted in systemic issues — management of change, asset integrity, human factors, emergency planning — that apply beyond one specific industry.
- Enduring influence on safety practice: Cases still actively referenced in process safety training, investigation methodology, and regulatory guidance decades after they occurred.
This list deliberately mixes chemical plants, offshore platforms, fuel storage terminals, nuclear facilities, and fertilizer warehouses. Readers searching for major industrial accidents expect breadth, and the patterns that repeat across these different sectors are precisely what make the lessons transferable. A failure in permit-to-work coordination on an offshore platform in the North Sea teaches a maintenance manager at a chemical complex the same fundamental lesson about communication, isolation, and barrier integrity.
Top 10 Major Industrial Accidents and Lessons Learned
1) Flixborough, UK (1974) — Temporary Modifications Can Become Catastrophic
On June 1, 1974, a massive vapor cloud explosion destroyed the Nypro chemical works at Flixborough, killing 28 people on site and injuring 36 others. The blast damaged nearly 2,000 properties in the surrounding area. A temporary 20-inch bypass pipe connecting two reactors in the caprolactam production process failed under pressure, releasing an estimated 30 to 50 tonnes of cyclohexane. The vapor cloud ignited within seconds.
The bypass had been installed after a reactor developed a crack. No formal engineering assessment was carried out. No pressure testing was performed. The pipe assembly used inappropriate bellows and lacked adequate support. A colleague who spent years in chemical plant maintenance once described Flixborough as the case that made him understand a single sentence: “temporary is the most dangerous word in process engineering.” He was right. The modification was treated as a maintenance fix, not a design change. That distinction — between a repair and a modification — remains one of the most dangerous grey areas in industrial operations.
The systemic cause was not the pipe. It was the absence of a structured management of change process. No competent mechanical engineer reviewed the design. No hazard assessment considered the consequences of failure. The plant’s own procedures did not require such a review for what was classified internally as routine maintenance.
The Fix That Works: Every modification, no matter how “temporary,” should trigger a formal management of change review. The question is never “how long will this be in place?” — it is “what happens if this fails?”
Flixborough’s regulatory legacy was immediate. The UK government established the Advisory Committee on Major Hazards, which laid the intellectual groundwork for the Health and Safety at Work Act enforcement model and eventually the COMAH Regulations. The core lesson: uncontrolled modification and inadequate engineering review can defeat every other safety system a plant possesses.
2) Seveso, Italy (1976) — Toxic Release Changed European Industrial Law
Two years after Flixborough, a runaway chemical reaction at the ICMESA plant near Seveso released a toxic cloud containing TCDD — one of the most potent dioxins known. The release contaminated a wide area of the Lombardy region, forced mass evacuations, and caused lasting health effects including chloracne and long-term concerns about carcinogenic exposure.
Seveso’s physical consequences were severe, but its regulatory consequences reshaped an entire continent’s approach to industrial risk. The accident exposed a fundamental gap: no European framework existed for identifying hazardous installations, requiring prevention measures, mandating emergency plans, or informing communities about the risks on their doorstep.
The European Community responded with the original Seveso Directive in 1982, revised as Seveso II in 1996, and now operating as the Seveso III Directive (2012/18/EU). Seveso III explicitly aims to prevent major accidents involving dangerous substances, limit their consequences for human health and the environment, and identify and promote lessons learned. It requires operators to produce major accident prevention policies, submit safety reports for upper-tier sites, develop on-site and off-site emergency plans, and provide public information about nearby hazards.
I have reviewed safety reports at chemical storage facilities where the Seveso classification determined everything — staffing levels, emergency response infrastructure, regulator inspection frequency, even how close new residential construction could be approved. The directive is not abstract law. It dictates physical reality on the ground.
The core lesson from Seveso: hazardous installations need strong inventory control, rigorous land-use planning, and genuine off-site emergency preparedness. Prevention alone is insufficient. Communities must be protected when prevention fails.
3) Bhopal, India (1984) — Process Safety and Community Protection Cannot Be Separated
Shortly after midnight on December 3, 1984, a storage tank at the Union Carbide pesticide plant in Bhopal released approximately 40 tonnes of methyl isocyanate (MIC) gas into the surrounding city. The toxic cloud drifted through densely populated neighborhoods. Estimates of the death toll vary, but Britannica’s current summary places it at 15,000 to 20,000 deaths, with around 500,000 survivors affected by exposure. Bhopal is widely regarded as the worst industrial disaster in history by any measure of human harm.
Multiple safety systems that should have prevented or mitigated the release were non-functional. The refrigeration unit for the MIC storage tank was shut down. The gas scrubber was undersized and out of service. The flare tower was disconnected for maintenance. The water curtain could not reach the height of the gas release. Staffing had been reduced. Maintenance backlogs had grown. Management attention had shifted away from safety-critical systems at a plant that was operating at a fraction of its intended capacity.
A process safety trainer I worked with years ago used a single slide for Bhopal. It showed a diagram of every barrier that should have functioned — refrigeration, scrubbing, flaring, water curtain, alarm, evacuation — with a red “X” through each one. His point was devastatingly simple: Bhopal did not fail because of one broken barrier. It failed because every barrier was broken simultaneously, and nobody was measuring whether any of them worked.
The core lesson: major accident prevention requires independent, verified, maintained barriers. When a facility stores or processes highly hazardous materials near populated areas, the obligation to maintain those barriers is absolute. Community risk communication, off-site emergency planning, and toxic release dispersion modeling are not optional add-ons. They are core safety functions.

4) Piper Alpha, UK North Sea (1988) — Permit-to-Work and Shift Handover Failures Kill Offshore
On July 6, 1988, an explosion and fire on the Piper Alpha platform in the UK North Sea killed 167 of the 228 people on board. It remains one of the deadliest offshore disasters in history. The initial release came from a condensate pump that had been taken offline for maintenance. A pressure safety valve had been removed and a blind flange fitted in its place. When the night shift started the pump — unaware of the incomplete maintenance — condensate leaked from the open pipework and ignited.
The permit-to-work system failed to communicate the status of the maintenance job across shifts. The handover was inadequate. The control room did not have clear visibility of which equipment was safe to operate. Once the initial fire escalated, the platform’s emergency systems could not contain it. Gas risers from connected platforms continued feeding the fire because emergency shutdown procedures were not activated quickly enough. Evacuation routes were blocked. The accommodation module became a death trap.
Lord Cullen’s public inquiry produced 106 recommendations that fundamentally restructured offshore safety regulation in the UK. The HSE maintains the inquiry report as a core reference. The UK moved from a prescriptive regulatory model to a goal-setting safety case regime. Every offshore operator was required to produce a safety case demonstrating that major accident risks were identified, assessed, and controlled.
Audit Point: Review your permit-to-work system not for procedural compliance on paper, but for one specific question: if a maintenance job is suspended at shift change, can the incoming shift physically verify the isolation status before restarting equipment?
The core lesson: permit-to-work, maintenance isolation, shift handover, and emergency response are safety-critical activities. Treating them as administrative paperwork rather than operational barriers is a direct path to catastrophe.
5) Exxon Valdez, Alaska (1989) — Environmental Impact Is an HSE Outcome
On March 24, 1989, the oil tanker Exxon Valdez ran aground on Bligh Reef in Prince William Sound, Alaska, spilling an estimated 11 million gallons of crude oil into one of the most ecologically sensitive marine environments on earth. The spill contaminated over 1,300 miles of coastline and devastated marine wildlife populations.
This was not a plant explosion. Nobody died in the grounding itself. Yet the Exxon Valdez qualifies as a major industrial accident because the scale of environmental harm was catastrophic, the organizational failures were systemic, and the consequences reshaped regulatory expectations for maritime operations and spill response globally.
Investigation findings pointed to crew fatigue, inadequate vessel traffic monitoring, reduced manning, and supervision failures. The third mate was navigating through a challenging passage after the master had left the bridge. Fatigue management was functionally nonexistent. The spill response was slow, under-resourced, and overwhelmed by conditions.
During an environmental impact assessment I supported at a coastal fuel terminal, the operations manager kept a framed photograph of oil-soaked seabirds from the Valdez cleanup on his office wall. When I asked why, he said it reminded him that the “E” in HSE is not a footnote — it is an outcome that the public remembers long after injury statistics are forgotten. That stayed with me.
The core lesson: operational discipline, fatigue management, and emergency readiness protect ecosystems as well as workers. A major accident can be “major” without an explosion if the environmental and societal harm is severe enough.
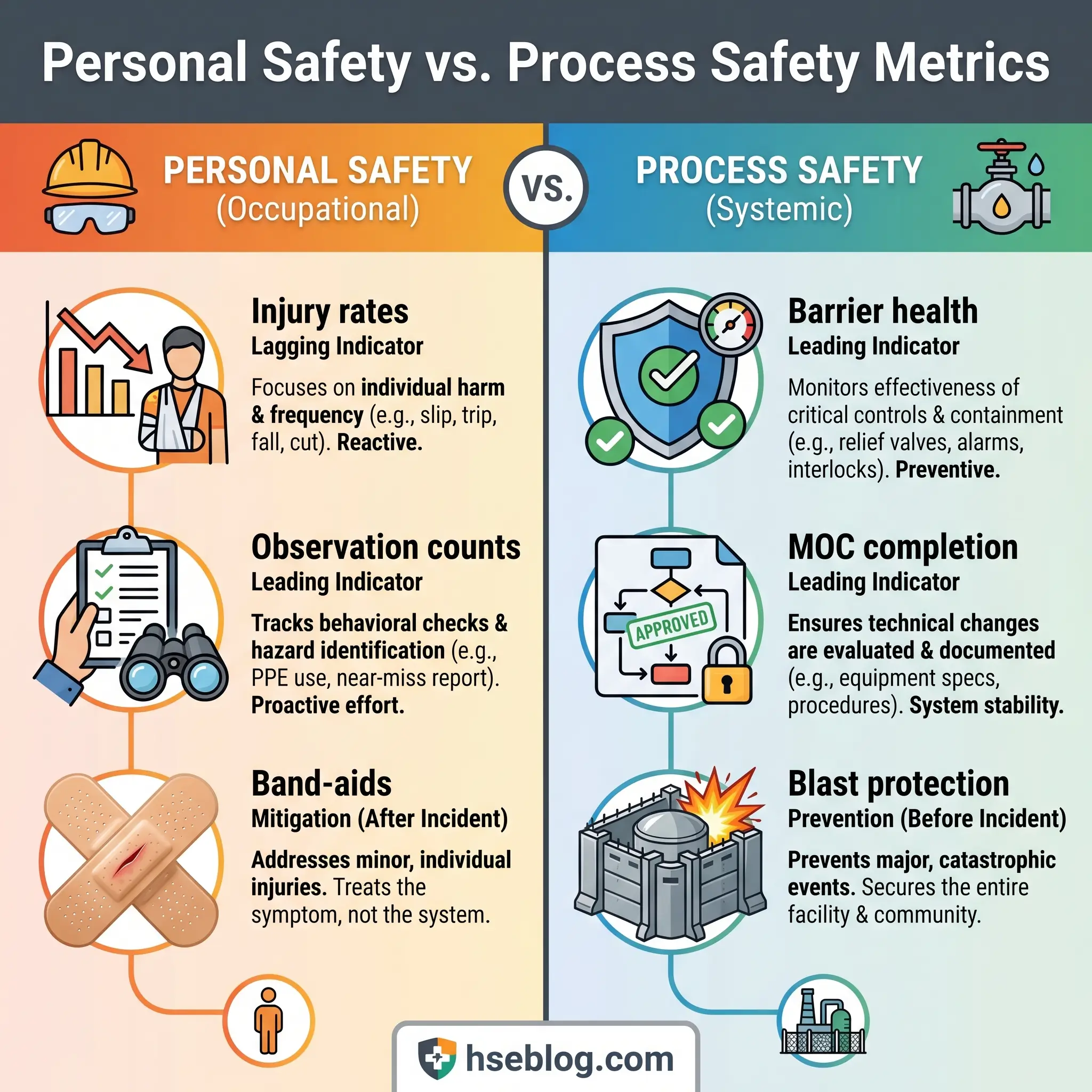
6) BP Texas City Refinery, USA (2005) — Personal Safety Metrics Do Not Equal Process Safety
On March 23, 2005, an explosion at the BP Texas City refinery killed 15 workers and injured 180 others. The blast occurred during the startup of an isomerization unit. A distillation tower was overfilled with hydrocarbon liquid. The blowdown drum and stack vented flammable liquid and vapor at ground level. The vapor cloud found an ignition source — likely a running diesel truck — and detonated.
Occupied trailers had been placed dangerously close to the process unit, within the blast zone. Many of the dead and injured were contractor workers inside those trailers who had no involvement in the startup operation.
The CSB investigation identified organizational and safety deficiencies at all levels. BP had relied heavily on personal safety metrics — lost-time injury rates, recordable incident rates — as evidence that the refinery was safe. Those metrics looked acceptable. They measured slips, trips, and falls. They did not measure whether safety-critical equipment functioned, whether startup procedures were followed, whether pressure relief pathways were clear, or whether occupied buildings were sited outside blast radii.
“We were counting band-aids while bombs were being built.” That was how a process safety specialist described it during a seminar I attended years later. The phrase was blunt, but it captured the central failure: the refinery’s safety management system was measuring the wrong things.
Field Test: Pull your facility’s last 12 months of safety KPIs. Count how many measure personal safety (injury rates, near-miss reports, observations) versus process safety (safety-critical equipment testing, demand rates on relief devices, overdue inspection items, MOC completion rates). If the ratio is heavily skewed toward personal safety, your measurement system has the same blind spot Texas City had.
The core lesson from BP Texas City: measure and manage major accident risk directly. Good personal safety performance can coexist with catastrophic process risk. OSHA’s PSM standard (29 CFR 1910.119) exists precisely to prevent or minimize consequences of catastrophic releases — but only if facilities implement it as a living system, not a compliance archive.
7) Buncefield, UK (2005) — Overfill Protection, Fuel Storage Monitoring, and Leadership Matter
On December 11, 2005, a massive vapor cloud explosion at the Buncefield oil storage depot in Hertfordshire, UK, produced one of the largest peacetime explosions in Europe. The blast and subsequent fire destroyed the terminal and caused widespread damage to surrounding commercial properties. Remarkably, no one was killed — but the event exposed serious deficiencies in how the UK managed major hazard sites in the fuel storage sector.
The immediate cause was an overfill of a large gasoline storage tank. The tank’s automatic gauge failed. The independent high-level switch — the last line of defense — also failed. Fuel overflowed, cascaded down the tank walls, and formed a massive vapor cloud that drifted across the site before igniting.
What made Buncefield’s investigation particularly revealing was its examination of the governance, leadership, and management culture that allowed instrumentation to deteriorate. HSE’s 2025 anniversary assessment states that Buncefield led to profound operational, technical, regulatory, and leadership changes across the UK’s fuel storage sector. The Process Safety Leadership Group was established. Competency requirements were tightened. Independent safeguard testing became a regulatory expectation, not a voluntary best practice.
I once walked a tank farm audit at a bulk fuel terminal where the site manager told me that before Buncefield, high-level switch testing was “something we got around to.” After Buncefield, it became a weekly documented activity with regulatory reporting consequences. That shift — from discretionary maintenance to mandated verification — is the essence of what the Buncefield investigation demanded.
The core lesson: high-consequence, low-frequency sites need robust independent alarms, verified safeguards with documented testing, and leadership that treats asset integrity as a governance responsibility rather than a maintenance task.
8) Deepwater Horizon / Macondo, Gulf of Mexico (2010) — Major Accident Risk Requires Barrier Management
On April 20, 2010, an uncontrolled hydrocarbon release from the Macondo well blew out through the drilling riser, engulfed the Deepwater Horizon drilling rig in gas and fire, killed 11 workers, and initiated a subsea oil spill that lasted 87 days. The CSB’s investigation documented how multiple barriers — cement integrity, negative pressure testing, well monitoring, blowout preventer activation — all failed in sequence.
The parallels to Texas City were explicit. CSB findings noted that the industry and regulators had not effectively learned key lessons from the BP Texas City disaster five years earlier. The same organizational pattern repeated: overreliance on lagging safety indicators, insufficient process safety competence at decision-making levels, and a culture where production pressure was not effectively counterbalanced by independent safety challenge.
Deepwater Horizon forced a global rethinking of offshore barrier management. The concept that every major hazard must be controlled by multiple independent barriers — and that the health of each barrier must be actively monitored, not assumed — became central to post-Macondo offshore safety regulation. The UK’s safety case regime, which had evolved continuously since Piper Alpha, was already structured around this principle. Other jurisdictions accelerated their adoption of similar frameworks.
Watch For: Any situation where a negative test result is explained away rather than investigated. At Macondo, anomalous pressure readings during the negative pressure test were rationalized. The well was declared stable when it was not. The willingness to accept a convenient explanation over a concerning data point is a failure mode that transcends offshore drilling.
The core lesson: high-hazard work needs barrier verification at every stage, independent technical challenge of critical decisions, and process safety indicators that go beyond lagging injury rates. When multiple barriers must hold simultaneously, each one must be proven — not presumed.
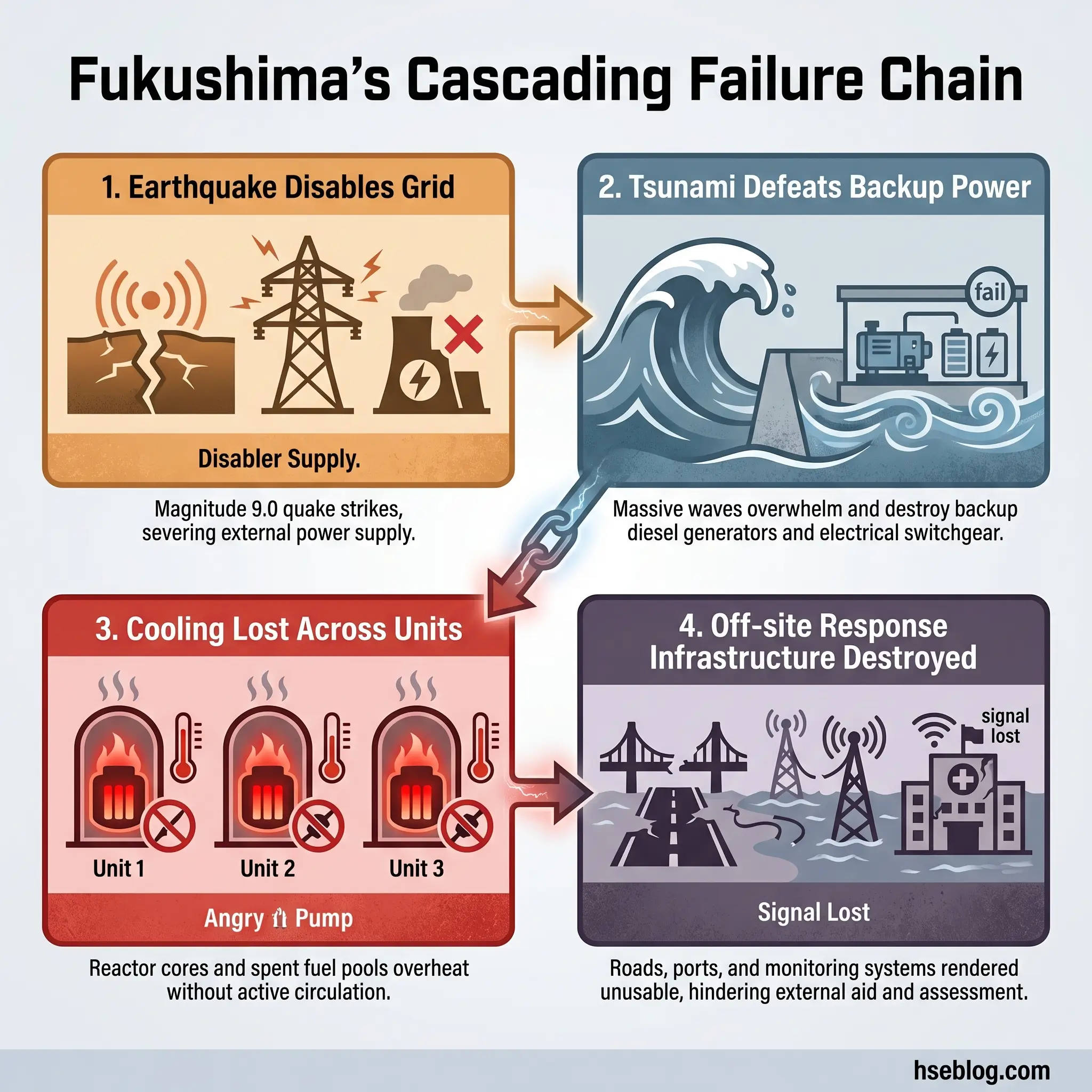
9) Fukushima Daiichi, Japan (2011) — Natural Hazards Must Be Integrated into Industrial Risk
On March 11, 2011, a magnitude 9.0 earthquake off the Pacific coast of Japan triggered a massive tsunami that struck the Fukushima Daiichi nuclear power station. The tsunami exceeded the plant’s design basis, disabled backup power systems, and caused the loss of reactor cooling in three units. Hydrogen explosions damaged reactor buildings. Radioactive material was released, forcing the evacuation of approximately 154,000 people from the surrounding area.
Fukushima introduced a concept to many industrial safety practitioners that seismologists and emergency planners had understood for years: Natech risk — natural hazard-triggered technological accidents. The earthquake and tsunami did not just damage the plant. They simultaneously destroyed roads, disabled communication systems, overwhelmed hospitals, disrupted supply chains, and made it physically impossible for response teams to reach the site with the equipment and personnel they needed.
The IAEA’s Fukushima lessons highlight that disruptions caused on and off site by extreme natural hazards created major logistical and operational problems, and that access, transport, and trained personnel are critical elements that cannot be assumed available during a severe event.
I participated in an emergency response tabletop exercise at a chemical complex located in a seismically active coastal zone. The scenario involved a moderate earthquake followed by a tsunami warning. Within the first hour of the exercise, every assumption about mutual aid response times, road access, utility supply, and off-site emergency services had collapsed. The exercise facilitator paused and asked: “What is your plan when nothing you planned for works?” That question — born directly from Fukushima — changed how that facility designed its emergency arrangements.
The core lesson: design basis assumptions must be challenged against extreme and cascading events. Emergency plans that rely on infrastructure, personnel, and logistics remaining intact during the very disaster that triggers the emergency are fundamentally flawed.
10) West Fertilizer, USA (2013) — Hazard Awareness and Land-Use Planning Save Lives
On April 17, 2013, a fire at the West Fertilizer Company storage facility in West, Texas, led to a massive detonation of approximately 40 to 60 tonnes of ammonium nitrate. The explosion killed 15 people — including 12 first responders — destroyed more than 150 buildings, and damaged a school and a nursing home located within the blast radius.
The CSB investigation centered its recommendations on prior fertilizer-grade ammonium nitrate incidents, the known incompatibility hazards of the material, failures in pre-incident planning, and the need for risk-based on-scene decision-making by emergency responders. First responders entered the facility to fight the fire without adequate knowledge of the quantity of ammonium nitrate stored, its detonation potential under fire conditions, or the safe standoff distance.
The land-use planning failure was equally stark. A school, a nursing home, and residential homes sat within the destructive radius of an ammonium nitrate storage facility. No regulatory mechanism had prevented this proximity. No off-site consequence analysis had been required or performed.
A fire service liaison officer I worked with on an industrial emergency planning committee described West Fertilizer as “the case that taught responders the hardest lesson: sometimes the bravest thing you can do is not go in.” His point was not about courage. It was about informed decision-making. Responders cannot make risk-based decisions about materials they have not been trained to recognize, in quantities they have not been told about, at distances that nobody calculated.
The core lesson: hazardous material storage must be paired with trained emergency responders who understand the specific hazards, adequate separation distances from vulnerable populations, and community-aware siting decisions that are enforced before facilities are built — not reviewed after they explode.
What Patterns Repeat Across Major Industrial Accidents?
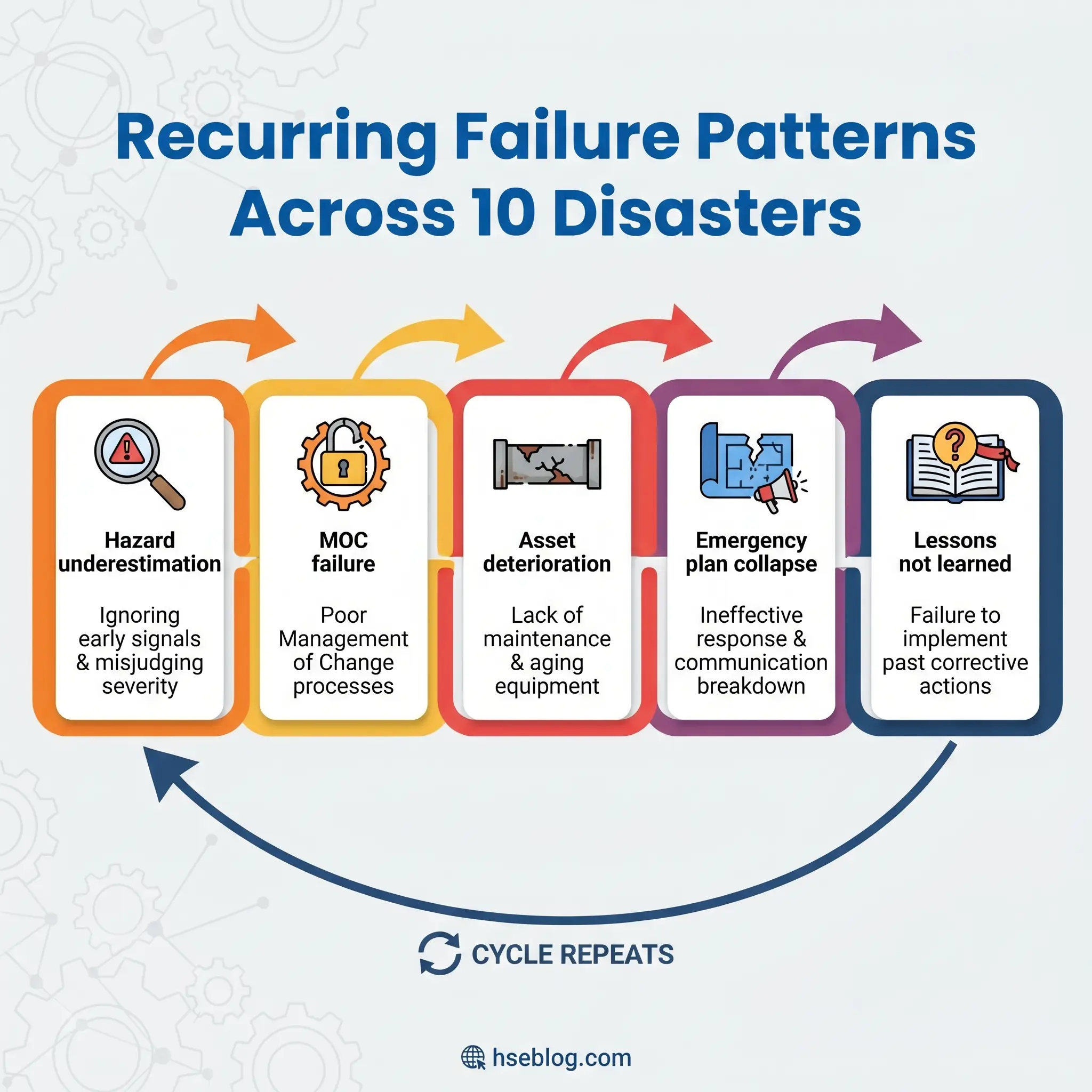
Moving from ten individual disasters to the systemic patterns they share is where historical knowledge becomes operational prevention. Every industrial accident case study on this list shares at least three of the following failure patterns — and most share five or more.
- Weak hazard identification and underestimation of worst-case scenarios: Facilities consistently failed to imagine — or chose not to analyze — the realistic worst case. Bhopal, Fukushima, and West Fertilizer all involved consequences that exceeded what operators had prepared for, despite the hazards being well-documented in technical literature.
- Management of change failures: Flixborough is the textbook case, but temporary modifications, undocumented process changes, and “temporary” fixes that became permanent features appear across multiple incidents. MOC is one of the 14 elements of OSHA PSM for exactly this reason.
- Poor maintenance and deteriorating asset integrity: Safety-critical equipment — relief valves, alarms, shutdown systems, gauges — was non-functional at the time of the accident in Bhopal, Buncefield, and Piper Alpha. Deferred maintenance on safety systems is deferred survival.
- Inadequate alarm and safeguard independence: At Buncefield, the high-level switch and the automatic gauge both failed. At Bhopal, every mitigation layer was offline. Independent safeguards must be genuinely independent — tested separately, maintained separately, and verified separately.
- Contractor management and shift handover breakdowns: Piper Alpha’s initiating event was a permit-to-work failure across shifts. Texas City’s casualties were largely contractors in poorly sited trailers. The interfaces between organizations and between shifts are where critical information is lost.
- Land-use planning and building siting failures: Occupied trailers at Texas City. A school and nursing home at West Fertilizer. Dense residential neighborhoods at Bhopal and Seveso. Separation distance is a control measure. When it is absent, consequences escalate from industrial to societal.
- Emergency planning that collapsed under real conditions: Fukushima’s response infrastructure was destroyed by the event it was supposed to respond to. West Fertilizer’s responders lacked the hazard information needed for risk-based decisions. Emergency plans must be stress-tested against realistic failure scenarios, not ideal conditions.
- Confusion between occupational safety and process safety performance: BP Texas City had acceptable personal injury rates while sitting on catastrophic process risk. Deepwater Horizon repeated the pattern five years later. Measuring the wrong things provides false assurance.
- Human factors, fatigue, and decision pressure: The Exxon Valdez grounding, Macondo’s rationalization of pressure test anomalies, and shift-change communication failures at Piper Alpha all involved human beings making poor decisions under fatigue, time pressure, or ambiguity — conditions that system design should anticipate and mitigate.
- Failure to learn from earlier incidents: CSB explicitly noted that lessons from Texas City had not been effectively applied before Macondo. Ammonium nitrate explosions have recurred across decades. The organizational discipline to seek out, internalize, and act on external lessons learned is consistently the weakest link in process safety management.
Which Regulations and Frameworks Changed Because of These Accidents?
The regulatory landscape that governs major hazard facilities today was not designed in a vacuum. It was written in response to the failures documented above. Understanding which accident drove which regulation transforms compliance from a bureaucratic exercise into a historical obligation.
OSHA Process Safety Management (29 CFR 1910.119) applies to facilities handling highly hazardous chemicals above threshold quantities. Its stated purpose is to prevent or minimize consequences of catastrophic releases of toxic, reactive, flammable, or explosive chemicals. The standard requires 14 interrelated elements — including process hazard analysis, operating procedures, mechanical integrity, management of change, incident investigation, and emergency planning. Texas City and Bhopal are the disasters most directly cited in PSM’s rationale.
EPA Risk Management Program (40 CFR Part 68) requires facilities holding extremely hazardous substances above threshold quantities to develop and submit a Risk Management Plan. The EPA’s RMP rule covers accident prevention, emergency preparedness, and community-facing risk controls. The 2024 final rule revisions introduced stronger requirements for incident investigation, third-party auditing at certain facilities, natural hazard evaluation, and community notification. Reconsideration activity continued in 2025, and in February 2026, EPA proposed additional changes — making this one of the most actively evolving regulatory frameworks in chemical accident prevention.
Seveso III Directive (2012/18/EU) and the UK COMAH Regulations 2015 represent the European and UK frameworks for major accident hazard control. Seveso III requires prevention policies, safety reports, emergency plans, land-use planning controls, and public information. The European Commission’s 2025 implementation report noted that EU member states are better equipped under Seveso III, and that major industrial accidents averaged fewer than 22 per year between 2019 and 2022 across the EU — a figure that reflects both improved prevention and more consistent reporting.
ILO Convention C174 and the Prevention of Major Industrial Accidents framework provide the international template for countries developing their own major hazard legislation. The ILO framework calls for an administrative, legal, and technical system covering identification of major hazard installations, hazard assessment, and establishment of preventive and emergency arrangements. It is particularly relevant for countries without mature domestic process safety legislation.
Each of these frameworks exists because an accident demonstrated that voluntary safety management was insufficient. The regulations are not arbitrary. They are codified lessons, paid for in lives.
How to Apply the Lessons at Your Facility
Historical knowledge has no operational value until it changes what happens on a site tomorrow morning. The ten accidents above — and the patterns they share — translate into a practical set of actions that any facility handling hazardous materials, energy, or processes can apply. This is not a generic checklist. Each item maps directly to a failure mode documented in the cases above.
- Revalidate your major accident scenarios. Include low-frequency, high-consequence events — not just the “credible” scenarios that fit neatly into a risk matrix. Fukushima and Bhopal both exceeded what their operators considered realistic. Challenge your design basis assumptions with extreme-event thinking.
- Audit management of change — especially temporary modifications. Flixborough’s lesson is 50 years old and still being relearned. Walk your plant and identify every temporary fix, bypass, jumper, or workaround that has been in place for more than one shift rotation. If any lack a formal MOC review, that is your highest-priority corrective action.
- Review asset integrity and safety-critical element performance. Do not assume safety-critical equipment works because it was installed and commissioned. Buncefield’s gauges failed. Bhopal’s scrubber and refrigeration were offline. Establish a testing and verification regime for every safety-critical element, with documented evidence of function.
- Strengthen startup, shutdown, permit-to-work, and shift handover controls. Texas City exploded during startup. Piper Alpha’s initiating event was a handover failure. These transitional states — startup, shutdown, handover, abnormal operation — are where major accidents concentrate. Your procedures for these phases should be more rigorous than steady-state operations, not less.
- Reassess siting of occupied buildings and community interfaces. If contractors, office workers, or members of the public are within the consequence radius of your worst-case scenario, that is a risk control gap. Texas City and West Fertilizer both demonstrated that proximity kills people who have no involvement in the process that failed.
- Stress-test your emergency response. Run exercises that simulate infrastructure failure, not just hazard activation. What happens when the road is blocked, the mutual aid crew is unavailable, communications are down, and the backup generator does not start? Fukushima proved that an emergency plan is only as resilient as the weakest link in its logistics chain.
- Track process safety indicators with the same rigor as personal safety metrics. Monitor demand rates on safety-critical devices, overdue inspection items, MOC backlog, safety-critical maintenance deferrals, and alarm system health. Texas City and Macondo both showed that personal safety KPIs can paint a reassuring picture while process safety risk escalates unchecked.
- Capture and share external lessons learned. CSB reports, HSE guidance, Seveso implementation summaries, and IAEA lessons are publicly available. Build a structured process for reviewing external incidents, extracting applicable lessons, and incorporating them into your own training, hazard reviews, and procedures. The failure to learn from other people’s disasters is the single most preventable failure pattern on this list.

Frequently Asked Questions
The industry’s collective memory is short, and that is the most dangerous failure pattern of all. Every accident on this list generated reports, recommendations, regulations, and reforms. The physical evidence has been cleared. The legal proceedings have concluded. The standards have been updated. And yet the patterns repeat — not because the technical solutions are unknown, but because organizations lose the discipline to sustain them. Asset integrity programs are funded during periods of regulatory attention and quietly eroded when budgets tighten. Management of change processes are followed rigorously after an incident and gradually relaxed as institutional memory fades. Process safety indicators are tracked until leadership attention shifts to the next priority.
The one lesson that matters more than any individual case study is this: the distance between a safe facility and a catastrophic failure is not measured in years of incident-free operation. It is measured in the current health of your barriers, the honesty of your hazard assessments, the rigor of your change controls, and the willingness of your organization to act on what it knows — including what it has learned from other people’s disasters. Every accident above was preceded by a period where the facility believed it was safe. The question worth asking is not whether your facility has had an incident. It is whether your facility could survive the scrutiny that follows one.